 打印
打印
智慧林草创新团队研发可持续学习领域知识的林业预训练语言模型(ForestryBERT)
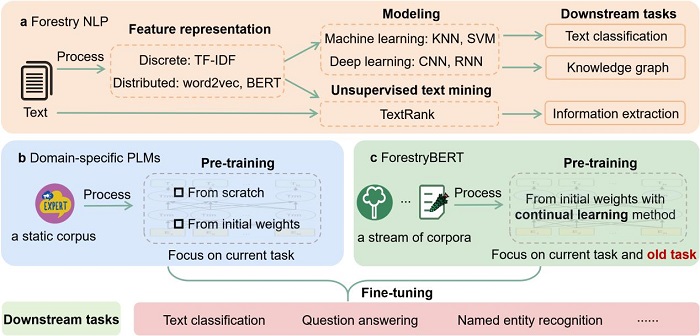
预训练语言模型是通过从海量文本中学习丰富语义信息,使其具备理解和生成自然语言文本的强大语言表征能力,可为知识服务提供重要支撑。通用预训练语言模型大多使用特定领域语料库进行继续预训练,以弥补领域专业知识的不足,增强模型的专业理解能力。现有研究普遍依赖固定语料库进行“一次性预训练”,难以适应和满足文本持续增长、知识动态更新的实际需求。虽然通过多次预训练模拟可以进行知识更新,但容易引发旧知识的灾难性遗忘,导致模型在学习新知识时丢失原有知识,难以实现模型的持续学习和知识积累。
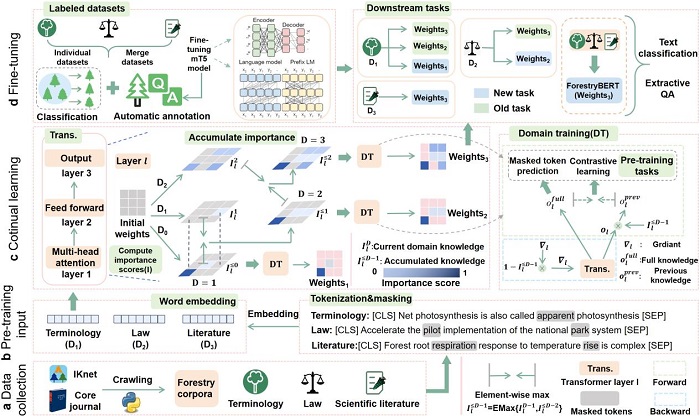
针对上述难题,资源所智慧林草创新团队研发了一种可持续学习领域知识的林业预训练语言模型(ForestryBERT)。该模型实现了三项关键技术突破:一是通过对林业术语、林业法律法规、林业文献等大规模动态语料库的学习,为模型提供了丰富多元的知识来源,使模型能精准捕捉林业语义信息,提升了模型对林业文本的理解能力;二是融合了持续学习方法,构建了动态知识吸收机制,通过软掩码技术与对比学习策略,使模型在面对不断更新的林业知识时,既能高效吸收新知识,又能适当保留旧知识,有效缓解了灾难性遗忘问题,提升了模型的适应性和稳定性;三是研发了多任务评估体系,准确评测模型在林业文本分类和林业抽取式问答中的性能,使模型具有较好的泛化性。综上所述,ForestryBERT通过构建一套通用的技术体系,突破了通用预训练语言模型难以应对林业知识动态更新的难题,实现了从动态变化的林业语料库中持续学习新知识并有效记忆旧知识,显著提高了模型的环境适应性和理解能力。
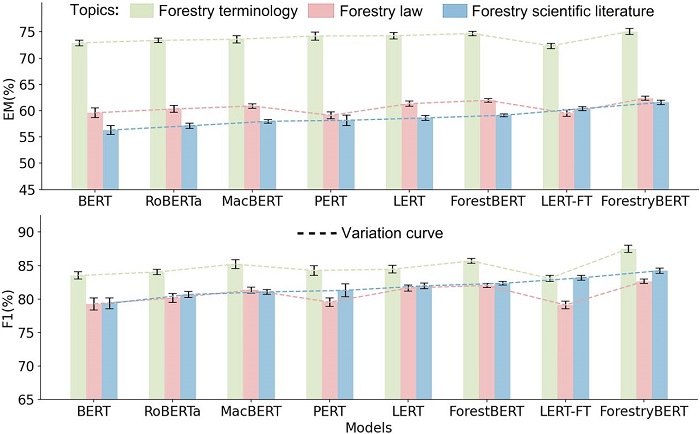
ForestryBERT是在智慧林草创新团队研发的问答式林业预训练语言模型(ForestBERT)基础上的又一重要技术突破,ForestryBERT通过与学习了同样林业知识但未采取持续学习机制的5种领域预训练语言模型的对比结果表明:ForestryBERT性能表现最好,知识遗忘率降低68.5%,具备可持续性和可扩展性。这一成果为林业文本处理提供了创新策略,为林草行业大模型-林龙大模型中林草大语言模型的研发提供了核心技术支撑,也为构建其他行业预训练语言模型提供了可借鉴的思路。
研究论文“ForestryBERT: A pre-trained language model with continual learning adapted to changing forestry text”一文发表在《Knowledge-Based Systems》(中科院一区TOP,IF=7.2),资源所硕士生谭晶维为第一作者,张怀清研究员为通讯作者。该项研究得到国家重点研发计划政府间国际科技创新合作项目(2022YFE0128100)和国家自然科学基金项目(32271877)的联合资助。
引文信息:Tan J W, Zhang H Q, Yang J, et al. ForestryBERT: A pre-trained language model with continual learning adapted to changing forestry text[J]. Knowledge-Based Systems, 2025: 113706.(谭晶维)
中国林科院 2025-05-14


关键词 林业预训练语言模型 ForestryBERT 图片
-
相关记录
更多
- 大兴安岭松岭林业局抢抓时机育新苗 2025-05-15
- 森林防火知识进校园 安全“种子”播心间 2025-05-15
- 守护亚洲象公益科普展在四川成都举办 2025-05-15
- 资源所完成的《大兴安岭林业集团公司森林可持续经营总体设计》通过专家评审 2025-05-15
- 祁连雪山邂逅“高原隐士”雪豹 2025-05-14
- 桉树生态营林 鱼和熊掌兼得 2025-05-13


